引用本文: 許佳藝, 代展菁, 盧鈺瓊, 路云, 常峰. 匹配調整間接比較應用的方法學要點和實踐現狀分析. 中國循證醫學雜志, 2024, 24(3): 322-330. doi: 10.7507/1672-2531.202310035 復制
版權信息: ?四川大學華西醫院華西期刊社《中國循證醫學雜志》版權所有,未經授權不得轉載、改編
隨著新興衛生技術不斷涌現,療效比較研究日益成為患者臨床治療方案選擇的重要指導依據。其中,頭對頭隨機對照試驗始終是療效對比的金標準,但現實情況下,多數創新藥因臨床急需性,大多基于單臂試驗結果通過附條件審批上市。此時非頭對頭隨機對照試驗引起的跨試驗差異可能造成方案間療效比較結果的偏倚。對此,英國國家衛生與臨床優化研究所(National Institute for Health and Care Excellence,NICE)[1]、澳大利亞藥品福利咨詢委員會[2]和德國衛生保健質量與效率研究所[3]等官方機構的藥物經濟學指導文件中均指出,需重視間接比較的跨試驗差異,并使用適當的間接比較方法對其進行調整以減少偏倚,提高結果可靠性。
目前常用的間接比較方法包括Meta分析、網狀Meta分析、Meta回歸、傾向評分匹配(propensity score matching,PSM)、匹配調整間接比較(matching-adjusted indirect comparison,MAIC)和模擬治療比較(simulated treatment comparison,STC)等,實際應用中研究者可根據數據可得情況選擇適當的方法。Meta分析或網狀Meta分析適用于干預措施僅可獲得匯總數據(aggregate data,AgD)的情況[4];Meta回歸和PSM適用于兩種干預措施可獲取對應臨床試驗的個體數據(individual patient data,IPD)的情況[5,6];MAIC和STC適用于一種干預措施可獲得IPD,而另一種干預措施可獲得AgD的情況。其中,MAIC于2010年由Signorovitch等[7]提出,基于逆傾向評分加權的思想,使用距估計法計算IPD試驗個體入組AgD試驗的概率并對IPD進行重新加權,從而創建一個與AgD組具有平衡距的“偽樣本”,以均衡跨試驗差異,實現IPD組療效結果的標準化,提升療效結果間的可比性[1,8]。相較于STC,MAIC可獲得更為精準的估計結果[9],是目前被廣泛接受且常用的方法。由于MAIC的操作過程較為復雜,研究者在數據來源和樣本選擇、匹配變量篩選、相對療效計算、研究內容報告等實踐操作方面存在差異[10,11],這容易導致MAIC研究質量參差不齊,也不利于后續藥品價值比較,即藥物經濟學研究的展開。
因此,本研究基于方法學研究文獻總結MAIC應用的方法學要點,同時對MAIC應用文獻開展系統評價,明晰MAIC應用現狀以及與藥物經濟學研究的銜接情況,總結現存問題和良好實踐經驗,并基于此提出優化建議,助力MAIC的科學使用,提高藥品間療效對比和價值對比的結果可信度,進而為醫保談判等衛生決策提供高質量證據。
1 MAIC應用的方法學要點
1.1 資料與方法
計算機檢索PubMed、Web of Science、Cochrane Library等數據庫以及英國NICE、國際藥物經濟學與結果研究學會(International Society for Pharmacoeconomics and Outcomes Research,ISPOR)等官方機構網站,以獲取MAIC方法學研究相關文獻,由于MAIC于2010年被首次提出,故檢索時限均為2010年1月至2023年8月。檢索采用主題詞與自由詞相結合的方式進行,并根據各數據庫特點進行調整。以PubMed為例,其具體檢索策略見附件框1。納入介紹MAIC方法學的文獻,排除MAIC應用研究、非中英文文獻、無法獲取的文獻和重復發布的研究。通過檢索并篩選,獲取4項研究[1,7,12,13],對納入文獻進行引文索引后,再納入1項研究[14]。通過閱讀納入文獻,并對MAIC應用步驟及其具體做法等內容進行資料提取,本研究歸納了MAIC應用的五大步驟,總結各步驟的方法學要點。
1.2 MAIC關鍵步驟與方法學要點
1.2.1 步驟1:數據來源和樣本選擇
根據目標人群、治療階段等條件進行系統檢索和篩選,確定各干預措施的療效數據來源。目標干預措施的IPD數據多取自臨床試驗,若有多個試驗可匯總IPD數據;對照措施的AgD數據來源除臨床試驗外,還可取自綜述或Meta分析等二次研究,若有多個來源可對其進行敏感性分析。若干預措施和對照措施無共同對照組(即分別開展A、B的單臂試驗),則進行非錨定MAIC進行調整,若有共同對照組(即分別開展A比C、B比C的臨床試驗)則進行錨定MAIC。
篩選數據來源時需確保所選試驗特征(如試驗設計、指標定義等)具有可比性,且AgD組納入與排除標準范圍應當小于IPD組[13],確定療效數據來源后,需按照AgD組納入與排除標準重新對IPD樣本進行篩選,為后續匹配做準備。
1.2.2 步驟2:匹配變量篩選
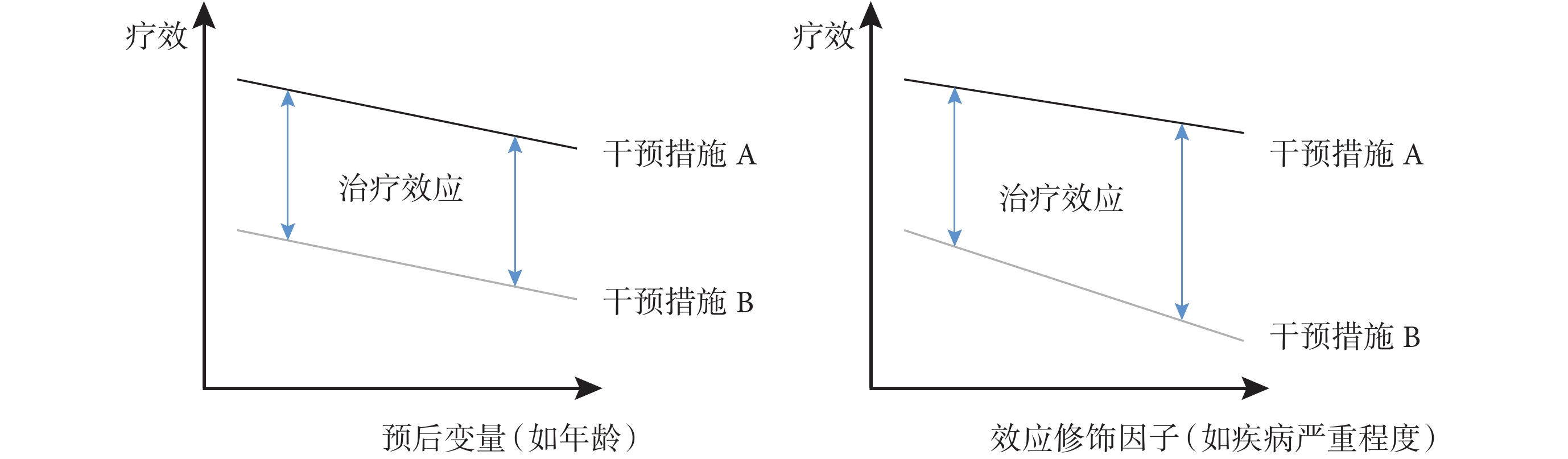
匹配變量指需匹配調整的非均衡變量(即跨試驗差異),在MAIC中主要指兩組人群的基線特征差異,包括預后變量和效應修飾因子兩種類型。預后變量指影響臨床結局的因素,與干預措施無關,即影響絕對效應;效應修飾因子指改變治療對臨床結局影響的因素,即影響治療相對效應。預后變量和效應修飾因子與療效的關系見圖1。
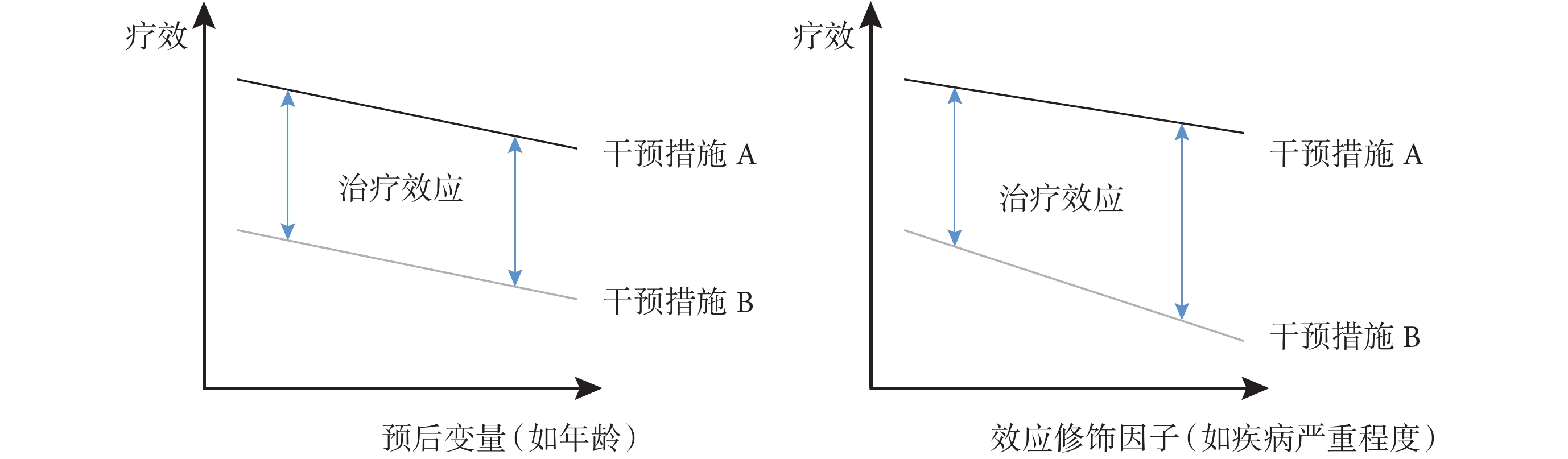 圖1
預后變量和效應修飾因子與療效的關系
圖1
預后變量和效應修飾因子與療效的關系
首先,基于步驟1確定的數據來源,篩選兩種干預措施的可匹配變量,需確保其在定義、評估方式等方面具有可比性[13]。匹配變量可為二分類或連續型變量,匹配后二分類變量的比例,以及連續型變量的均值和高階項均能實現均衡。
其次,判斷匹配變量類型并根據研究類型篩選對應的匹配變量。對于匹配變量類型,NICE的指導文件[1]指出,需通過外部定量研究、臨床咨詢或參考已有文獻進行判斷;Gregory等[14]提出還可通過參考臨床試驗亞組分析結果進行判斷。對于匹配變量納入,NICE文件[1]指出非錨定MAIC存在強假設,即兩組試驗療效結局間的差異完全可以用預后變量和效應修飾因子的不平衡來解釋,故應調整所有效應修飾因子和預后變量;錨定MAIC應調整所有效應修飾因子,但不應調整純粹的預后變量以避免過度匹配[1];同時,要求列舉可用變量及其分布(如繪制直方圖等反應各試驗間特征重合性),要求研究報告匹配變量的篩選過程,以提升報告規范性。
1.2.3 步驟3:個體權重計算
在非錨定MAIC中,假定兩種干預措施的臨床試驗分別為A(IPD數據)和B(AgD數據),此時需要估計的權重WiA為第i個個體入組試驗B與入組試驗A的概率之比,一般通過Logistic回歸模型估計獲得(公式1)。其中,XiA表示基于步驟2獲得的試驗A的匹配變量向量,如年齡、性別、疾病嚴重程度等,i表示試驗A中第i個個體。由于試驗B僅有AgD數據,無法通過標準方法估計回歸參數,Signorovitch等[7]提出使用距估計獲得參數估計值以精確平衡兩組協變量的均值,該步驟可通過軟件計算獲得(如SAS軟件)。
 |
在錨定MAIC中,A和B存在共同對照組C,假定兩種干預措施的臨床試驗分別為AC和BC,此時需要估計的權重Wit為第i個個體入組試驗BC與入組試驗AC的概率之比,i表示試驗AC中第i個個體,t表示干預措施(t=A或C),估計思路同上,計算見公式2。
 |
1.2.4 步驟4:匹配效度評估
根據步驟3獲得的個體權重,可計算有效樣本量(effective sample size,ESS)來評估此次匹配的效度。ESS為試驗A(非錨定)或試驗AC(錨定)加權后的樣本量,其數值介于0和IPD組樣本總量之間,越大證明匹配效果越好,越小則說明兩組試驗人群重疊程度較低,此時療效估計值不確定性大,ESS計算見公式3和公示4。Gregory等[14]還提出對每個個體權重進行調整獲得重新縮放權重Wre i(rescaled weights),見公式5,當Wrei>1時,表示該個體在加權總體中的權重高于原始數據;反之則低于原始數據,更易判斷某個體的權重變化。
 |
其中,NA為試驗A樣本量,WiA為試驗A中第i個個體的權重。
 |
其中,Nt(AC)為試驗AC中干預措施t組樣本量,Wit為試驗AC中干預措施t組的第i個個體的權重。
 |
其中,Wi為各試驗中第i個個體的權重,N為各試驗樣本量。
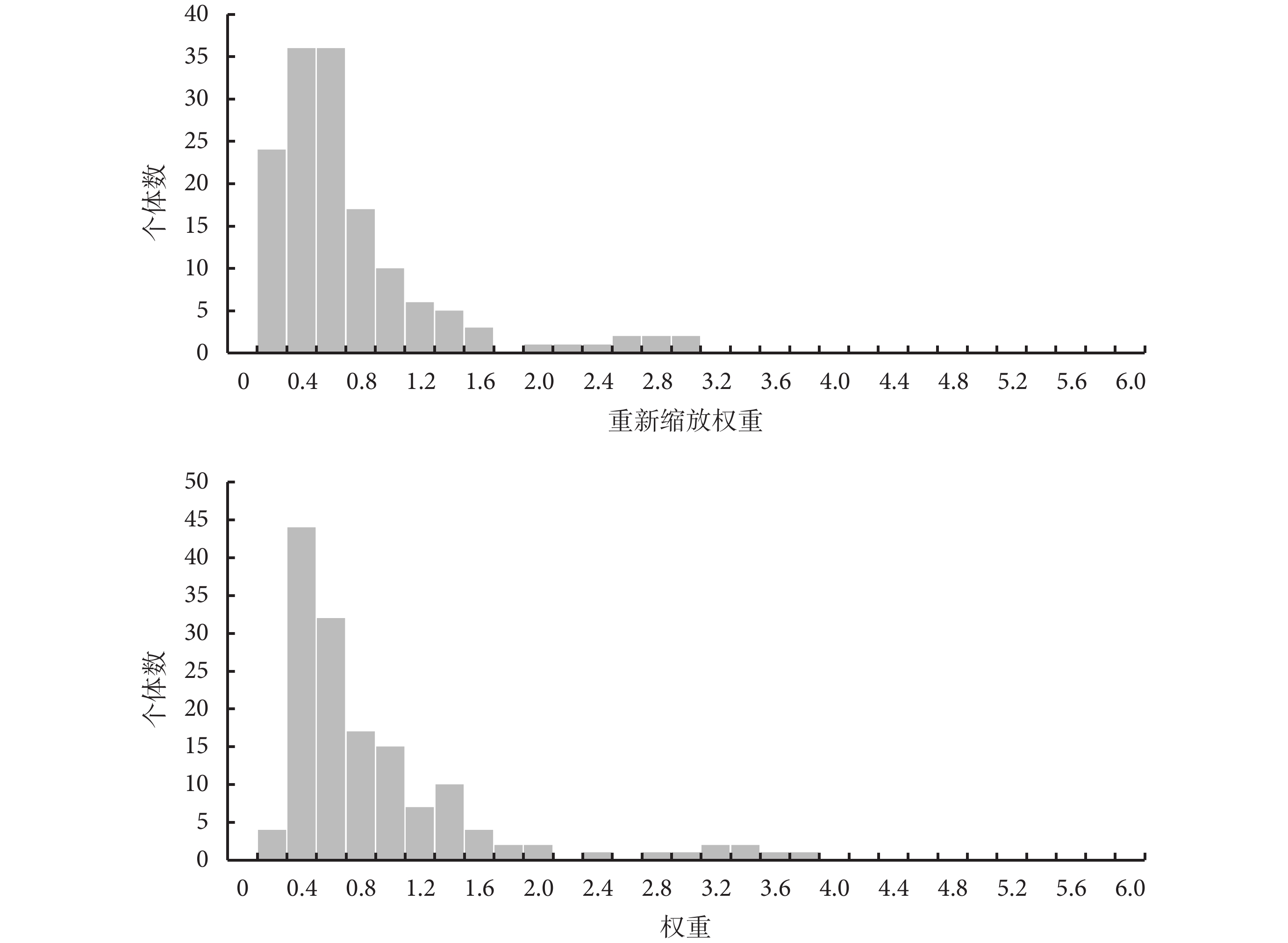
NICE文件[1]要求呈現權重分布體現重疊程度(圖2),以提升報告規范性。
 圖2
權重分布示例圖
圖2
權重分布示例圖
1.2.5 步驟5:相對療效計算
使用步驟3獲得的個體權重調整結局指標獲得相對療效估計值,結局指標可為二分類指標、連續型指標或時間事件指標等。在非錨定研究中,YiA表示結局指標向量,如緩解率、總生存(overall survival,OS)時間、無進展生存(progression-free survival,PFS)時間等,其中i表示試驗A中第i個個體。干預措施A在試驗B人群中療效結局的估計值 可通過公式6計算獲得,其中NA為試驗A樣本量。
可通過公式6計算獲得,其中NA為試驗A樣本量。
 |
在錨定研究中,結局指標向量表示為Yit,干預措施t(A或C)在試驗BC人群中的療效結局的估計值 的計算思路同上,見公式7,其中Nt(AC)為試驗AC中干預措施t組的樣本量。
的計算思路同上,見公式7,其中Nt(AC)為試驗AC中干預措施t組的樣本量。
 |
上述相對療效計算在實際計算時,研究者需根據各結局指標的屬性在其對應量綱上進行具體化計算。
2 MAIC應用的實踐現狀
2.1 資料與方法
MAIC于2010年被提出,目前已有NICE文件[1]對2016年以前應用該方法的文獻進行綜述,并提出若干報告建議,因此本研究針對此后發表的應用文獻進行分析,以檢驗實踐現狀是否與建議一致。同時,考慮到非小細胞肺癌的療效比較涉及多種數據類型,也多使用MAIC,因此本研究檢索時限為2016年1月至2023年8月,系統評價非小細胞肺癌領域的MAIC應用文獻,并結合前述的MAIC應用步驟和要點,分析MAIC實踐現狀及問題。
計算機檢索PubMed、Web of Science、Cochrane Library、CNKI、VIP和WanFang Data等數據庫,檢索采用主題詞與自由詞相結合的方式進行,并根據各數據庫特點進行調整。以PubMed為例,其具體檢索策略見附件框2。納入使用MAIC方法進行非小細胞肺癌領域療效對比或藥物經濟學研究的文獻;排除非中英文文獻、無法獲取全文的文獻和重復發表的研究。由2名研究者獨立篩選文獻、提取資料并交叉核對。如有分歧,則通過討論或與第三方協商解決。
2.2 文獻篩選結果
初檢獲得相關文獻384篇,包括PubMed(n=87)、Web of Science(n=139)、Cochrane Library(n=11)、CNKI(n=77)、VIP(n=4)和WanFang Data(n=66)。經逐層篩選后,最終納入20項研究[10-11,15-32]。
2.3 MAIC應用現狀
納入的20項研究包括11項療效對比研究和9項藥物經濟學研究。療效對比研究中,9項應用非錨定MAIC,2項應用錨定MAIC。藥物經濟學研究中,3項引用了前述療效對比研究的風險比(hazard ratio,HR),其余4項應用非錨定MAIC,3項應用錨定MAIC。納入研究的基本特征見表1。
2.4 MAIC關鍵步驟的應用實踐
本部分針對納入的11項療效對比研究進行分析,由于藥物經濟學研究對MAIC方法要點論述較少故不納入。主要針對上述5個步驟分析實踐情況,考慮到已有研究多開展有敏感性分析故對其設置也進行歸納分析,同時基于NICE建議分析已有研究的報告規范性。
2.4.1 數據來源和樣本選擇
11項療效對比研究中,6項研究[11,15-19]通過文獻綜述系統篩選臨床試驗作為療效數據來源,其中2項研究[16,17]特別說明了對IPD數據重新進行納入與排除,與方法學文獻中推薦做法一致。
2.4.2 匹配變量篩選
11項療效對比研究中,8項研究說明了篩選依據,其中4項研究[15-18]綜合統計評估(Cox分析)、臨床咨詢和參考已有文獻確定匹配變量,3項研究[20,21,23]納入所有可匹配的變量,1項研究[10]僅通過Cox分析確定匹配變量篩選。
2.4.3 個體權重計算
在實際應用中,個體權重按照前述公式,借助軟件計算獲得。11項療效對比研究中,9項說明了統計分析軟件,其中3項[10,15,22]使用R,且Smith等[15]說明使用NICE文件[1]提出的代碼進行計算,3項研究[16-18]使用SAS軟件,3項研究[11,21,23]同時使用R和SAS軟件;其余2項研究[19,20]未說明。
2.4.4 匹配效度評估
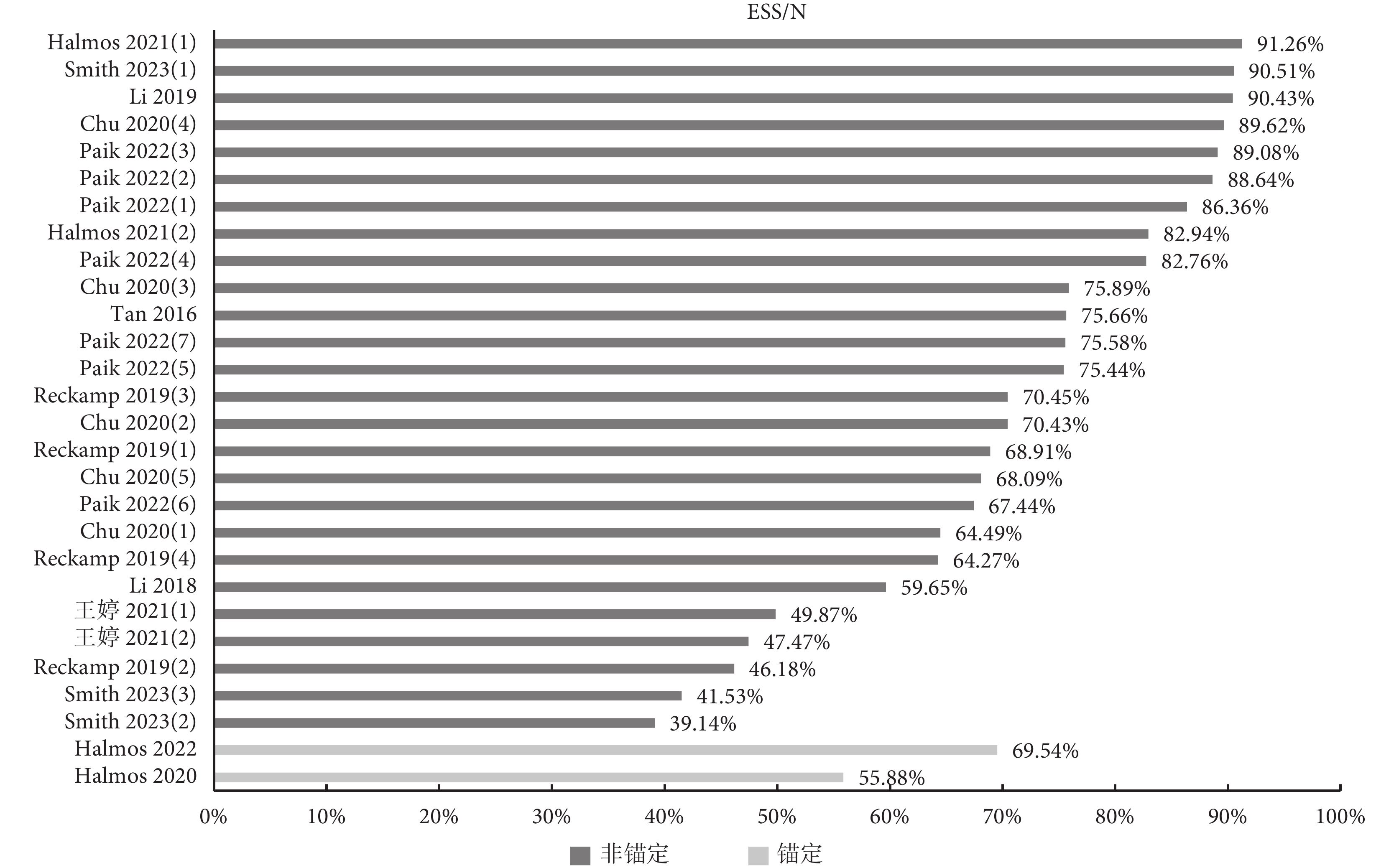
11項療效對比研究均報告了ESS,但僅Smith等[15]在附件中報告了權重分布圖。由于ESS在各研究中為一個介于0到樣本量(N)之間的值,各研究間直接進行橫向對比無實際意義,因此本研究計算各研究ESS與N的比值,以體現匹配后有效樣本的占比。納入研究共涉及28次匹配,即獲得28個ESS/N值(圖3)。結果顯示71.43%的ESS/N值大于60%,可見大部分研究匹配后有效樣本量較為充足。
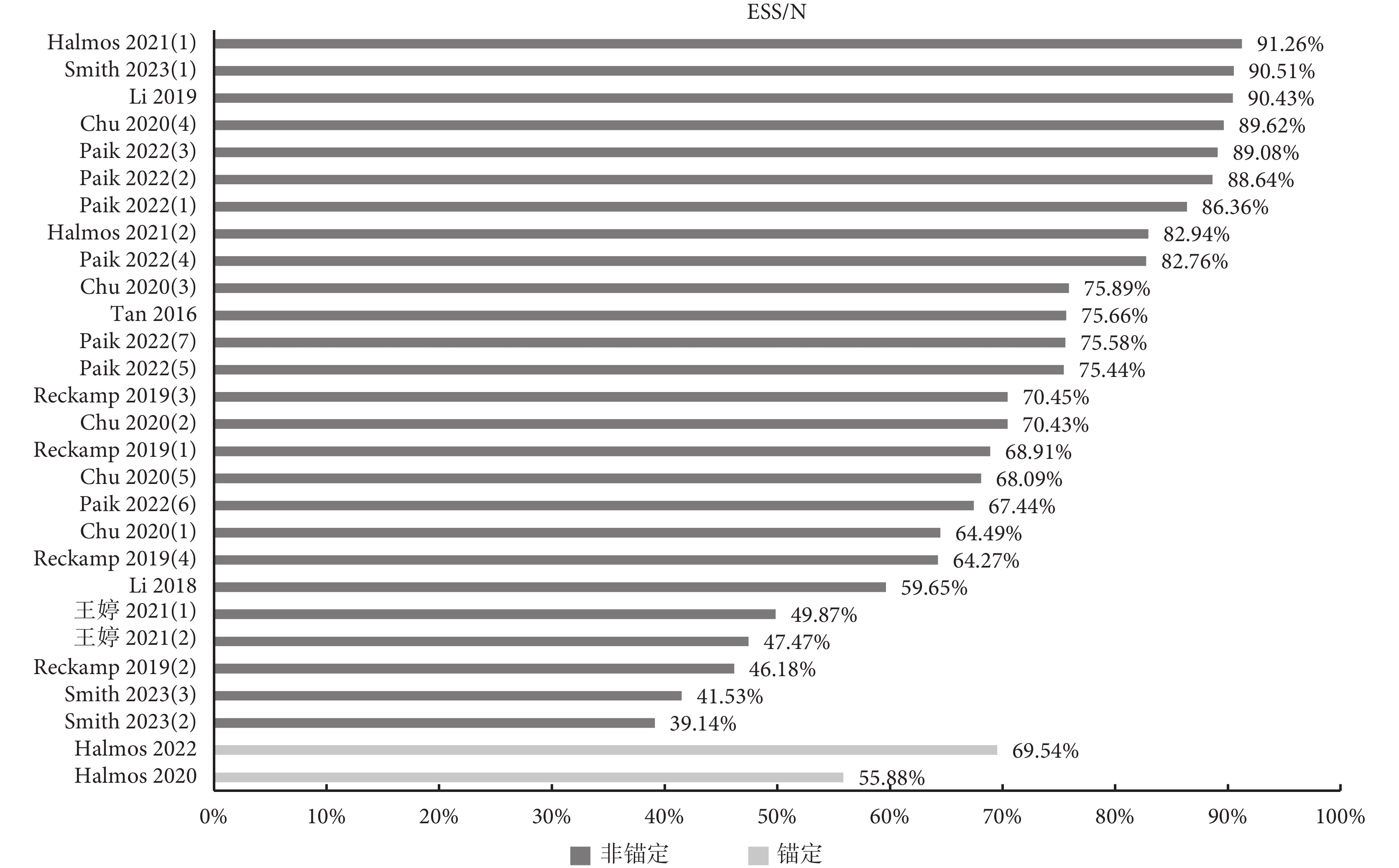 圖3
納入研究ESS/N值分布
圖3
納入研究ESS/N值分布
2.4.5 相對療效計算
納入研究中,結局指標包括時間事件指標(如OS、PFS)和二分類指標(如客觀緩解率、不良事件停藥率);其中時間事件指標的相對療效以HR呈現,二分類指標以比值比(odds ratio,OR)或相對危險度(relative risk,RR)呈現。
9項非錨定MAIC研究中,2項研究[11,22]未計算相對療效而僅計算加權調整后的結局指標數值,1項研究[10]未說明計算方法。其余提及相對療效的研究中,針對OS、PFS這類時間事件指標,6項研究[15,17,19-21,23]均使用加權Cox等比例風險模型計算HR;針對ORR等二分類指標,1項研究[17]使用廣義線性模型計算RR,1項研究[20]使用加權Logistic模型計算OR,1項研究[23]僅使用加權卡方檢驗評估兩組ORR是否有差異而未計算相對療效。
2項錨定MAIC研究[16,18]均說明使用加權Cox等比例風險模型計算時間事件指標的相對療效,但未說明針對二分類結局指標相對療效的計算方法。在HR計算方面,由于錨定MAIC中具體做法較為靈活且無統一標準,2項研究均介紹了兩種計算思路:第一種方法是較為常見的做法,將試驗AC與試驗BC匹配獲得權重后,使用加權Cox模型計算A比C的HR,再結合文獻報道B比C的HR,以C為錨定組計算獲得A比B的相對療效;第二種方法為獲得權重后,結合試驗AC中A的結局指標的IPD以及試驗BC中B的結局指標的偽IPD(取點擬合所得),使用加權Cox模型直接計算A比B的相對療效。
值得注意的是,使用Cox等比例風險模型計算的HR蘊含了等比例風險(porportional hazards,PH)的強假設,9項計算HR的療效對比研究中僅3項考慮了PH假設,其中2項研究[21,23]對匹配后的數據驗證PH假設,1項研究[17]僅對原始數據進行驗證。
2.4.6 敏感性分析
11項療效對比研究中,9項研究進行了敏感性分析,其中5項研究[15,19-21,23]納入不同數據來源,3項研究[10,16,18]設置不同患者亞組,3項研究[16-18]對不同隨訪截斷時間的結果進行敏感性分析(考慮到3項研究為同一研究者針對相同臨床試驗和干預措施進行研究,該設置可能不具有共性),2項研究[15,23]通過設置不同的匹配變量組合進行敏感性分析。
2.4.7 報告規范性
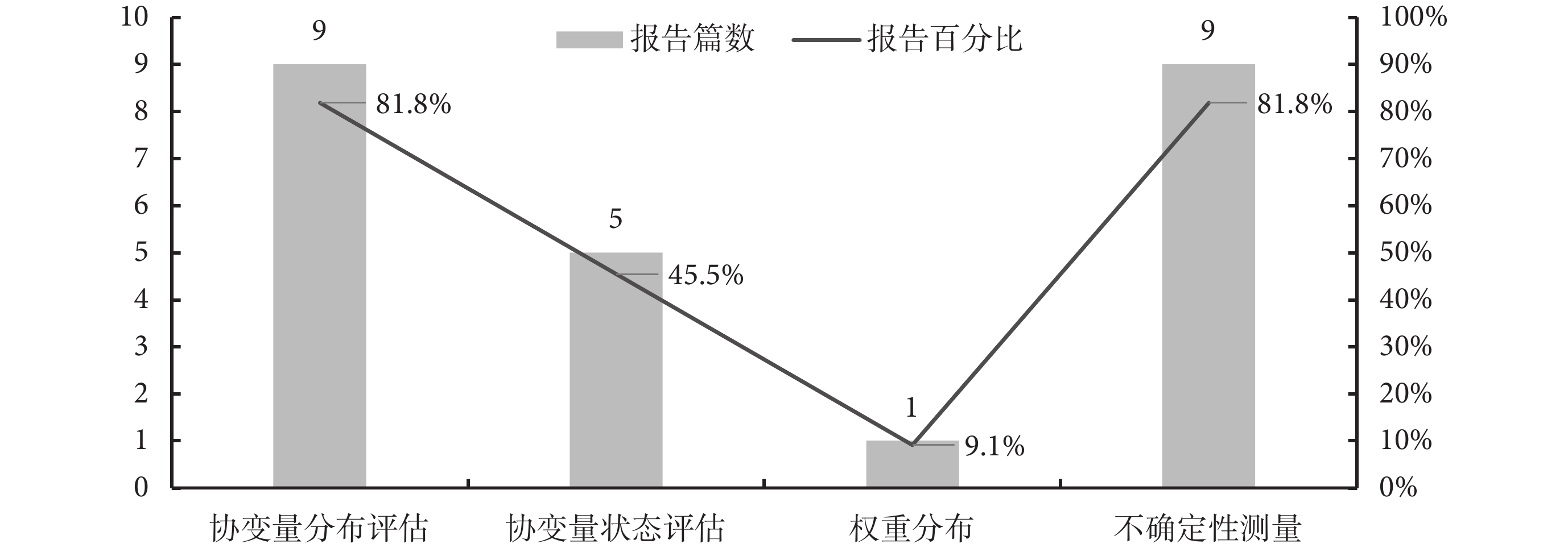
NICE文件[1]建議MAIC研究報告協變量分布評估、協變量狀態評估、權重分布、不確定性測量4項內容。11項療效對比研究的報告情況見圖4。協變量評估方面,8項研究[10,16-18,20-23]列舉了基線特征數據,僅1項研究[15]進行對比描述;協變量狀態評估方面,5項研究通過統計分析、臨床咨詢、參考文獻進行確定;在權重分布方面,僅1項研究[15]報告;在不確定性測量方面,9項研究[10,15-21,23]主要通過敏感性分析、報告置信區間、使用sandwich估計等方法體現不確定性。
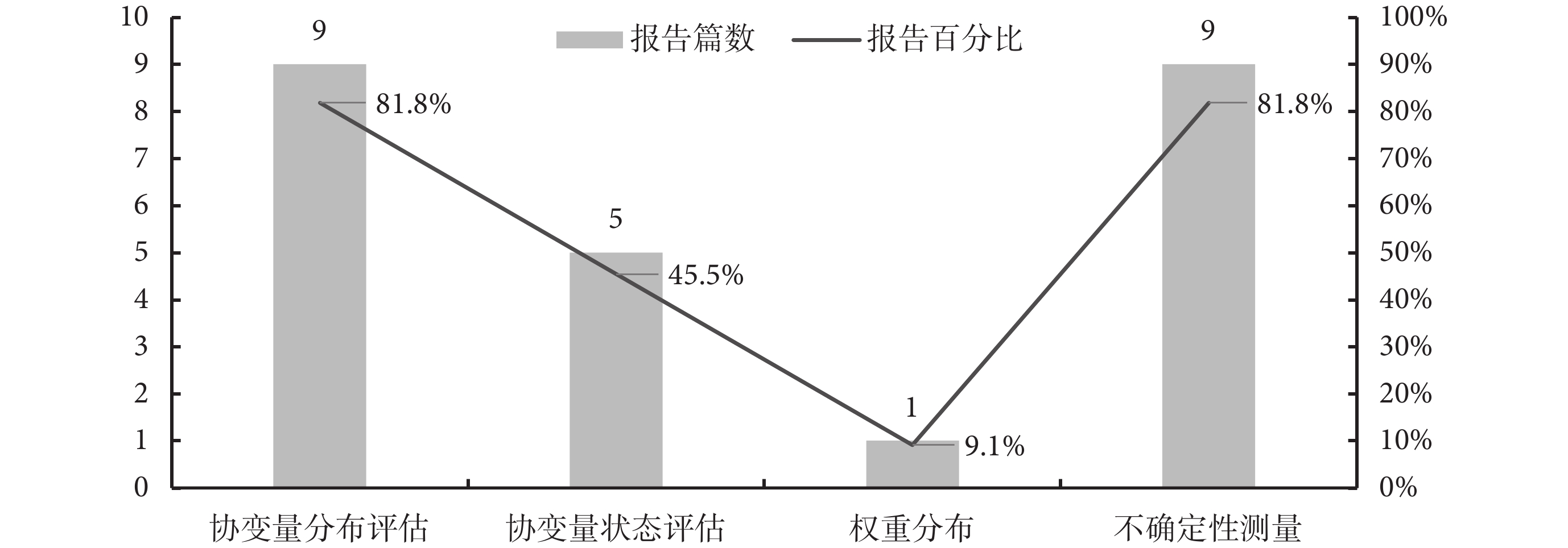 圖4
納入研究的報告規范性情況
圖4
納入研究的報告規范性情況
2.5 MAIC與藥物經濟學的銜接應用
本部分針對系統評價所納入的9項藥物經濟學研究進行分析。MAIC與藥物經濟學的銜接主要體現在將通過MAIC計算獲得的HR用于生存數據的擬合外推中,具體表現在外推參照組選擇和PH假設。
2.5.1 外推參照組選擇
9項藥物經濟學研究中,7項研究說明了擬合外推方法,其中6項研究[24,26,27,29,31,32]選擇目標藥品作為外推參照組,基于IPD采用標準參數法進行擬合外推,對照藥品在此基礎上使用HR調整獲得。1項研究[28]錨定研究考慮到試驗BC的OS不滿足PH,無法計算A比B的HR,也無法以目標藥品A為參照組對B進行外推,故選擇試驗BC中C的偽IPD作為外推參照組,使用A比C的HR進行A的擬合外推;而試驗BC的PFS滿足PH,故選擇B的偽IPD為外推參照組,使用A比B的HR進行A的擬合外推。
2.5.2 PH假設
由于生存數據的擬合外推依賴于HR,故藥物經濟學分析中更需注意兩種干預措施的療效數據是否滿足PH假設。9項藥物經濟學研究中,4項研究考慮了PH假設,其中1項研究[25]考慮到目標藥品作用機制相同直接假定滿足PH,1項研究[26]根據圖表結果說明放寬PH假設,即假設滿足,1項研究[27]未進行檢驗直接假設滿足PH,1項研究[28]僅對原始數據進行驗證。
3 討論
本研究對MAIC的方法原理和實踐應用進行了闡述與歸納,相較于已發表的MAIC介紹文獻[33],本研究側重研究關鍵步驟的基礎原理,細化了各步驟的應用要點,同時對2016年后在非小細胞肺癌領域使用MAIC的文獻進行系統評價,歸納分析MAIC在實際應用中各步驟的實踐現狀,并結合前述方法學要點,為MAIC的應用和報告規范方面提出建議,以期提升后續MAIC研究質量。相較于已有對MAIC和STC進行系統評價的文獻[34],本研究更聚焦MAIC,特別對其相對療效計算思路等應用細節進行分析,同時本研究還關注MAIC與藥物經濟學研究的銜接應用,為后續MAIC結果在藥物經濟學中的實際應用提出相應建議。
結合MAIC方法學原理可知,當進行兩種干預措施療效的間接比較,且可獲取一組IPD數據和一組AgD數據,為盡量減少跨試驗差異對療效對比結果的影響,推薦使用MAIC方法。
研究發現,由于創新藥開展單臂臨床試驗的現象較為普遍,在MAIC研究類型方面以非錨定研究居多。納入研究在數據來源和樣本選擇方面做法稍有欠缺,半數研究(54.4%,n=6)符合推薦做法,進行文獻綜述篩選數據來源,其余研究未說明篩選方法,可能會造成可用數據來源的遺漏,其中僅2項研究說明對IPD組數據按照AgD納入與排除標準重新進行篩選,其余研究無法確保兩組遵循統一的納入與排除標準。納入研究的匹配變量篩選依據較充分,72.7%(n=8)的研究進行了說明,現有較為科學的主流做法包括統計分析、臨床咨詢和參考已有文獻,其中統計分析主要為開展單因素和多因素Cox分析,這與NICE文件[1]和Gregory等[14]的建議一致,少數研究(n=3)未使用上述方法而直接納入所有可匹配變量,可能會因納入過多的匹配變量而導致過矯。個體權重計算等步驟多通過R或SAS軟件實現(81.8%,n=9)。納入研究的匹配效度評估報告充分,所有研究均報告了ESS,但僅1項研究報告權重分布情況,71.43%的ESS/N值大于60%,整體匹配效度較為合理。納入研究的相對療效結局指標以時間事件類型的結局指標為主,通過Cox模型計算獲得HR,針對二分類指標的計算方法包括廣義線性模型、Logistic模型等,實際做法存在一定差異;非錨定研究的HR計算方法和思路大致相同,但有錨定研究提出兩種不同的相對療效計算思路;計算HR的研究僅少數(33.3%,n=3)考慮了PH假設,且做法尚不統一。多數(81.8%,n=9)研究開展了敏感性分析以分析不確定性,設置方面包括不同數據來源、患者亞組、匹配變量組合等。根據NICE文件建議,納入研究報告規范性總體良好但各條目間差距較大,對協變量分布的評估和不確定性測量報告較多(81.8%,n=9),45.5%的研究報告了協變量狀態評估,但僅1項研究報告權重分布。
在MAIC與藥物經濟學研究的銜接方面,在說明擬合外推方法的文獻中多數(85.7%,n=6)研究選擇目標藥品作為生存數據擬合外推的參照組,但一項NICE審查報告[35]指出這與MAIC方法原理相矛盾,由于調整后的HR反映對照組人群中兩種措施的相對療效,因此建議將對照藥品作為外推參照組。藥物經濟學研究對PH假設的考慮同樣較少,僅44.4%(n=4)的研究說明,且3項研究放寬或假定滿足PH。
綜上,對后續MAIC研究提出以下建議:① 非錨定MAIC研究使用廣泛,需注意其強假設,即兩種干預措施的療效差異完全來源于預后變量和效應修飾因子的不平衡,因此研究時需更加謹慎;② 通過文獻綜述系統篩選數據來源,并依據對照組納入與排除標準對IPD重新進行納排,若可獲得多個合適對照組的數據來源,可考慮進行敏感性分析;③ 通過統計分析、臨床咨詢和參考已有文獻等科學方法對匹配變量進行系統篩選,在錨定MAIC中納入預后變量,在非錨定MAIC中納入預后變量和效應修飾因子,針對存疑的變量可通過設置不同匹配變量情境研究不確定性;④ 通過報告ESS和權重分布以體現匹配效度,同時報告權重為0的樣本數量[1],并盡可能確保較高的ESS/N值以減少樣本流失;⑤ 通過加權Cox模型計算HR后需考慮PH假設,若無法統一標準做法檢驗PH假設時,需將其作為研究局限性進行報告;⑥ 對NICE建議的協變量分布評估、協變量狀態評估、權重分布、不確定性測量4項內容進行報告,提升報告規范性;⑦ 在使用MAIC獲得的HR進行生存數據擬合外推時,更加謹慎地選擇外推參照組,同時也需對是否滿足PH假設進行相應報告。
同時,本研究也存在一定的局限性,主要體現在系統評價僅納入了非小細胞肺癌領域的研究,研究結論可能存在偏倚,在進行其他領域的MAIC研究時需注意外推合理性。
隨著新興衛生技術不斷涌現,療效比較研究日益成為患者臨床治療方案選擇的重要指導依據。其中,頭對頭隨機對照試驗始終是療效對比的金標準,但現實情況下,多數創新藥因臨床急需性,大多基于單臂試驗結果通過附條件審批上市。此時非頭對頭隨機對照試驗引起的跨試驗差異可能造成方案間療效比較結果的偏倚。對此,英國國家衛生與臨床優化研究所(National Institute for Health and Care Excellence,NICE)[1]、澳大利亞藥品福利咨詢委員會[2]和德國衛生保健質量與效率研究所[3]等官方機構的藥物經濟學指導文件中均指出,需重視間接比較的跨試驗差異,并使用適當的間接比較方法對其進行調整以減少偏倚,提高結果可靠性。
目前常用的間接比較方法包括Meta分析、網狀Meta分析、Meta回歸、傾向評分匹配(propensity score matching,PSM)、匹配調整間接比較(matching-adjusted indirect comparison,MAIC)和模擬治療比較(simulated treatment comparison,STC)等,實際應用中研究者可根據數據可得情況選擇適當的方法。Meta分析或網狀Meta分析適用于干預措施僅可獲得匯總數據(aggregate data,AgD)的情況[4];Meta回歸和PSM適用于兩種干預措施可獲取對應臨床試驗的個體數據(individual patient data,IPD)的情況[5,6];MAIC和STC適用于一種干預措施可獲得IPD,而另一種干預措施可獲得AgD的情況。其中,MAIC于2010年由Signorovitch等[7]提出,基于逆傾向評分加權的思想,使用距估計法計算IPD試驗個體入組AgD試驗的概率并對IPD進行重新加權,從而創建一個與AgD組具有平衡距的“偽樣本”,以均衡跨試驗差異,實現IPD組療效結果的標準化,提升療效結果間的可比性[1,8]。相較于STC,MAIC可獲得更為精準的估計結果[9],是目前被廣泛接受且常用的方法。由于MAIC的操作過程較為復雜,研究者在數據來源和樣本選擇、匹配變量篩選、相對療效計算、研究內容報告等實踐操作方面存在差異[10,11],這容易導致MAIC研究質量參差不齊,也不利于后續藥品價值比較,即藥物經濟學研究的展開。
因此,本研究基于方法學研究文獻總結MAIC應用的方法學要點,同時對MAIC應用文獻開展系統評價,明晰MAIC應用現狀以及與藥物經濟學研究的銜接情況,總結現存問題和良好實踐經驗,并基于此提出優化建議,助力MAIC的科學使用,提高藥品間療效對比和價值對比的結果可信度,進而為醫保談判等衛生決策提供高質量證據。
1 MAIC應用的方法學要點
1.1 資料與方法
計算機檢索PubMed、Web of Science、Cochrane Library等數據庫以及英國NICE、國際藥物經濟學與結果研究學會(International Society for Pharmacoeconomics and Outcomes Research,ISPOR)等官方機構網站,以獲取MAIC方法學研究相關文獻,由于MAIC于2010年被首次提出,故檢索時限均為2010年1月至2023年8月。檢索采用主題詞與自由詞相結合的方式進行,并根據各數據庫特點進行調整。以PubMed為例,其具體檢索策略見附件框1。納入介紹MAIC方法學的文獻,排除MAIC應用研究、非中英文文獻、無法獲取的文獻和重復發布的研究。通過檢索并篩選,獲取4項研究[1,7,12,13],對納入文獻進行引文索引后,再納入1項研究[14]。通過閱讀納入文獻,并對MAIC應用步驟及其具體做法等內容進行資料提取,本研究歸納了MAIC應用的五大步驟,總結各步驟的方法學要點。
1.2 MAIC關鍵步驟與方法學要點
1.2.1 步驟1:數據來源和樣本選擇
根據目標人群、治療階段等條件進行系統檢索和篩選,確定各干預措施的療效數據來源。目標干預措施的IPD數據多取自臨床試驗,若有多個試驗可匯總IPD數據;對照措施的AgD數據來源除臨床試驗外,還可取自綜述或Meta分析等二次研究,若有多個來源可對其進行敏感性分析。若干預措施和對照措施無共同對照組(即分別開展A、B的單臂試驗),則進行非錨定MAIC進行調整,若有共同對照組(即分別開展A比C、B比C的臨床試驗)則進行錨定MAIC。
篩選數據來源時需確保所選試驗特征(如試驗設計、指標定義等)具有可比性,且AgD組納入與排除標準范圍應當小于IPD組[13],確定療效數據來源后,需按照AgD組納入與排除標準重新對IPD樣本進行篩選,為后續匹配做準備。
1.2.2 步驟2:匹配變量篩選
匹配變量指需匹配調整的非均衡變量(即跨試驗差異),在MAIC中主要指兩組人群的基線特征差異,包括預后變量和效應修飾因子兩種類型。預后變量指影響臨床結局的因素,與干預措施無關,即影響絕對效應;效應修飾因子指改變治療對臨床結局影響的因素,即影響治療相對效應。預后變量和效應修飾因子與療效的關系見圖1。
圖1
預后變量和效應修飾因子與療效的關系
首先,基于步驟1確定的數據來源,篩選兩種干預措施的可匹配變量,需確保其在定義、評估方式等方面具有可比性[13]。匹配變量可為二分類或連續型變量,匹配后二分類變量的比例,以及連續型變量的均值和高階項均能實現均衡。
其次,判斷匹配變量類型并根據研究類型篩選對應的匹配變量。對于匹配變量類型,NICE的指導文件[1]指出,需通過外部定量研究、臨床咨詢或參考已有文獻進行判斷;Gregory等[14]提出還可通過參考臨床試驗亞組分析結果進行判斷。對于匹配變量納入,NICE文件[1]指出非錨定MAIC存在強假設,即兩組試驗療效結局間的差異完全可以用預后變量和效應修飾因子的不平衡來解釋,故應調整所有效應修飾因子和預后變量;錨定MAIC應調整所有效應修飾因子,但不應調整純粹的預后變量以避免過度匹配[1];同時,要求列舉可用變量及其分布(如繪制直方圖等反應各試驗間特征重合性),要求研究報告匹配變量的篩選過程,以提升報告規范性。
1.2.3 步驟3:個體權重計算
在非錨定MAIC中,假定兩種干預措施的臨床試驗分別為A(IPD數據)和B(AgD數據),此時需要估計的權重WiA為第i個個體入組試驗B與入組試驗A的概率之比,一般通過Logistic回歸模型估計獲得(公式1)。其中,XiA表示基于步驟2獲得的試驗A的匹配變量向量,如年齡、性別、疾病嚴重程度等,i表示試驗A中第i個個體。由于試驗B僅有AgD數據,無法通過標準方法估計回歸參數,Signorovitch等[7]提出使用距估計獲得參數估計值以精確平衡兩組協變量的均值,該步驟可通過軟件計算獲得(如SAS軟件)。
|
在錨定MAIC中,A和B存在共同對照組C,假定兩種干預措施的臨床試驗分別為AC和BC,此時需要估計的權重Wit為第i個個體入組試驗BC與入組試驗AC的概率之比,i表示試驗AC中第i個個體,t表示干預措施(t=A或C),估計思路同上,計算見公式2。
|
1.2.4 步驟4:匹配效度評估
根據步驟3獲得的個體權重,可計算有效樣本量(effective sample size,ESS)來評估此次匹配的效度。ESS為試驗A(非錨定)或試驗AC(錨定)加權后的樣本量,其數值介于0和IPD組樣本總量之間,越大證明匹配效果越好,越小則說明兩組試驗人群重疊程度較低,此時療效估計值不確定性大,ESS計算見公式3和公示4。Gregory等[14]還提出對每個個體權重進行調整獲得重新縮放權重Wre i(rescaled weights),見公式5,當Wrei>1時,表示該個體在加權總體中的權重高于原始數據;反之則低于原始數據,更易判斷某個體的權重變化。
|
其中,NA為試驗A樣本量,WiA為試驗A中第i個個體的權重。
|
其中,Nt(AC)為試驗AC中干預措施t組樣本量,Wit為試驗AC中干預措施t組的第i個個體的權重。
|
其中,Wi為各試驗中第i個個體的權重,N為各試驗樣本量。
NICE文件[1]要求呈現權重分布體現重疊程度(圖2),以提升報告規范性。
圖2
權重分布示例圖
1.2.5 步驟5:相對療效計算
使用步驟3獲得的個體權重調整結局指標獲得相對療效估計值,結局指標可為二分類指標、連續型指標或時間事件指標等。在非錨定研究中,YiA表示結局指標向量,如緩解率、總生存(overall survival,OS)時間、無進展生存(progression-free survival,PFS)時間等,其中i表示試驗A中第i個個體。干預措施A在試驗B人群中療效結局的估計值可通過公式6計算獲得,其中NA為試驗A樣本量。
|
在錨定研究中,結局指標向量表示為Yit,干預措施t(A或C)在試驗BC人群中的療效結局的估計值的計算思路同上,見公式7,其中Nt(AC)為試驗AC中干預措施t組的樣本量。
|
上述相對療效計算在實際計算時,研究者需根據各結局指標的屬性在其對應量綱上進行具體化計算。
2 MAIC應用的實踐現狀
2.1 資料與方法
MAIC于2010年被提出,目前已有NICE文件[1]對2016年以前應用該方法的文獻進行綜述,并提出若干報告建議,因此本研究針對此后發表的應用文獻進行分析,以檢驗實踐現狀是否與建議一致。同時,考慮到非小細胞肺癌的療效比較涉及多種數據類型,也多使用MAIC,因此本研究檢索時限為2016年1月至2023年8月,系統評價非小細胞肺癌領域的MAIC應用文獻,并結合前述的MAIC應用步驟和要點,分析MAIC實踐現狀及問題。
計算機檢索PubMed、Web of Science、Cochrane Library、CNKI、VIP和WanFang Data等數據庫,檢索采用主題詞與自由詞相結合的方式進行,并根據各數據庫特點進行調整。以PubMed為例,其具體檢索策略見附件框2。納入使用MAIC方法進行非小細胞肺癌領域療效對比或藥物經濟學研究的文獻;排除非中英文文獻、無法獲取全文的文獻和重復發表的研究。由2名研究者獨立篩選文獻、提取資料并交叉核對。如有分歧,則通過討論或與第三方協商解決。
2.2 文獻篩選結果
初檢獲得相關文獻384篇,包括PubMed(n=87)、Web of Science(n=139)、Cochrane Library(n=11)、CNKI(n=77)、VIP(n=4)和WanFang Data(n=66)。經逐層篩選后,最終納入20項研究[10-11,15-32]。
2.3 MAIC應用現狀
納入的20項研究包括11項療效對比研究和9項藥物經濟學研究。療效對比研究中,9項應用非錨定MAIC,2項應用錨定MAIC。藥物經濟學研究中,3項引用了前述療效對比研究的風險比(hazard ratio,HR),其余4項應用非錨定MAIC,3項應用錨定MAIC。納入研究的基本特征見表1。
2.4 MAIC關鍵步驟的應用實踐
本部分針對納入的11項療效對比研究進行分析,由于藥物經濟學研究對MAIC方法要點論述較少故不納入。主要針對上述5個步驟分析實踐情況,考慮到已有研究多開展有敏感性分析故對其設置也進行歸納分析,同時基于NICE建議分析已有研究的報告規范性。
2.4.1 數據來源和樣本選擇
11項療效對比研究中,6項研究[11,15-19]通過文獻綜述系統篩選臨床試驗作為療效數據來源,其中2項研究[16,17]特別說明了對IPD數據重新進行納入與排除,與方法學文獻中推薦做法一致。
2.4.2 匹配變量篩選
11項療效對比研究中,8項研究說明了篩選依據,其中4項研究[15-18]綜合統計評估(Cox分析)、臨床咨詢和參考已有文獻確定匹配變量,3項研究[20,21,23]納入所有可匹配的變量,1項研究[10]僅通過Cox分析確定匹配變量篩選。
2.4.3 個體權重計算
在實際應用中,個體權重按照前述公式,借助軟件計算獲得。11項療效對比研究中,9項說明了統計分析軟件,其中3項[10,15,22]使用R,且Smith等[15]說明使用NICE文件[1]提出的代碼進行計算,3項研究[16-18]使用SAS軟件,3項研究[11,21,23]同時使用R和SAS軟件;其余2項研究[19,20]未說明。
2.4.4 匹配效度評估
11項療效對比研究均報告了ESS,但僅Smith等[15]在附件中報告了權重分布圖。由于ESS在各研究中為一個介于0到樣本量(N)之間的值,各研究間直接進行橫向對比無實際意義,因此本研究計算各研究ESS與N的比值,以體現匹配后有效樣本的占比。納入研究共涉及28次匹配,即獲得28個ESS/N值(圖3)。結果顯示71.43%的ESS/N值大于60%,可見大部分研究匹配后有效樣本量較為充足。
圖3
納入研究ESS/N值分布
2.4.5 相對療效計算
納入研究中,結局指標包括時間事件指標(如OS、PFS)和二分類指標(如客觀緩解率、不良事件停藥率);其中時間事件指標的相對療效以HR呈現,二分類指標以比值比(odds ratio,OR)或相對危險度(relative risk,RR)呈現。
9項非錨定MAIC研究中,2項研究[11,22]未計算相對療效而僅計算加權調整后的結局指標數值,1項研究[10]未說明計算方法。其余提及相對療效的研究中,針對OS、PFS這類時間事件指標,6項研究[15,17,19-21,23]均使用加權Cox等比例風險模型計算HR;針對ORR等二分類指標,1項研究[17]使用廣義線性模型計算RR,1項研究[20]使用加權Logistic模型計算OR,1項研究[23]僅使用加權卡方檢驗評估兩組ORR是否有差異而未計算相對療效。
2項錨定MAIC研究[16,18]均說明使用加權Cox等比例風險模型計算時間事件指標的相對療效,但未說明針對二分類結局指標相對療效的計算方法。在HR計算方面,由于錨定MAIC中具體做法較為靈活且無統一標準,2項研究均介紹了兩種計算思路:第一種方法是較為常見的做法,將試驗AC與試驗BC匹配獲得權重后,使用加權Cox模型計算A比C的HR,再結合文獻報道B比C的HR,以C為錨定組計算獲得A比B的相對療效;第二種方法為獲得權重后,結合試驗AC中A的結局指標的IPD以及試驗BC中B的結局指標的偽IPD(取點擬合所得),使用加權Cox模型直接計算A比B的相對療效。
值得注意的是,使用Cox等比例風險模型計算的HR蘊含了等比例風險(porportional hazards,PH)的強假設,9項計算HR的療效對比研究中僅3項考慮了PH假設,其中2項研究[21,23]對匹配后的數據驗證PH假設,1項研究[17]僅對原始數據進行驗證。
2.4.6 敏感性分析
11項療效對比研究中,9項研究進行了敏感性分析,其中5項研究[15,19-21,23]納入不同數據來源,3項研究[10,16,18]設置不同患者亞組,3項研究[16-18]對不同隨訪截斷時間的結果進行敏感性分析(考慮到3項研究為同一研究者針對相同臨床試驗和干預措施進行研究,該設置可能不具有共性),2項研究[15,23]通過設置不同的匹配變量組合進行敏感性分析。
2.4.7 報告規范性
NICE文件[1]建議MAIC研究報告協變量分布評估、協變量狀態評估、權重分布、不確定性測量4項內容。11項療效對比研究的報告情況見圖4。協變量評估方面,8項研究[10,16-18,20-23]列舉了基線特征數據,僅1項研究[15]進行對比描述;協變量狀態評估方面,5項研究通過統計分析、臨床咨詢、參考文獻進行確定;在權重分布方面,僅1項研究[15]報告;在不確定性測量方面,9項研究[10,15-21,23]主要通過敏感性分析、報告置信區間、使用sandwich估計等方法體現不確定性。
圖4
納入研究的報告規范性情況
2.5 MAIC與藥物經濟學的銜接應用
本部分針對系統評價所納入的9項藥物經濟學研究進行分析。MAIC與藥物經濟學的銜接主要體現在將通過MAIC計算獲得的HR用于生存數據的擬合外推中,具體表現在外推參照組選擇和PH假設。
2.5.1 外推參照組選擇
9項藥物經濟學研究中,7項研究說明了擬合外推方法,其中6項研究[24,26,27,29,31,32]選擇目標藥品作為外推參照組,基于IPD采用標準參數法進行擬合外推,對照藥品在此基礎上使用HR調整獲得。1項研究[28]錨定研究考慮到試驗BC的OS不滿足PH,無法計算A比B的HR,也無法以目標藥品A為參照組對B進行外推,故選擇試驗BC中C的偽IPD作為外推參照組,使用A比C的HR進行A的擬合外推;而試驗BC的PFS滿足PH,故選擇B的偽IPD為外推參照組,使用A比B的HR進行A的擬合外推。
2.5.2 PH假設
由于生存數據的擬合外推依賴于HR,故藥物經濟學分析中更需注意兩種干預措施的療效數據是否滿足PH假設。9項藥物經濟學研究中,4項研究考慮了PH假設,其中1項研究[25]考慮到目標藥品作用機制相同直接假定滿足PH,1項研究[26]根據圖表結果說明放寬PH假設,即假設滿足,1項研究[27]未進行檢驗直接假設滿足PH,1項研究[28]僅對原始數據進行驗證。
3 討論
本研究對MAIC的方法原理和實踐應用進行了闡述與歸納,相較于已發表的MAIC介紹文獻[33],本研究側重研究關鍵步驟的基礎原理,細化了各步驟的應用要點,同時對2016年后在非小細胞肺癌領域使用MAIC的文獻進行系統評價,歸納分析MAIC在實際應用中各步驟的實踐現狀,并結合前述方法學要點,為MAIC的應用和報告規范方面提出建議,以期提升后續MAIC研究質量。相較于已有對MAIC和STC進行系統評價的文獻[34],本研究更聚焦MAIC,特別對其相對療效計算思路等應用細節進行分析,同時本研究還關注MAIC與藥物經濟學研究的銜接應用,為后續MAIC結果在藥物經濟學中的實際應用提出相應建議。
結合MAIC方法學原理可知,當進行兩種干預措施療效的間接比較,且可獲取一組IPD數據和一組AgD數據,為盡量減少跨試驗差異對療效對比結果的影響,推薦使用MAIC方法。
研究發現,由于創新藥開展單臂臨床試驗的現象較為普遍,在MAIC研究類型方面以非錨定研究居多。納入研究在數據來源和樣本選擇方面做法稍有欠缺,半數研究(54.4%,n=6)符合推薦做法,進行文獻綜述篩選數據來源,其余研究未說明篩選方法,可能會造成可用數據來源的遺漏,其中僅2項研究說明對IPD組數據按照AgD納入與排除標準重新進行篩選,其余研究無法確保兩組遵循統一的納入與排除標準。納入研究的匹配變量篩選依據較充分,72.7%(n=8)的研究進行了說明,現有較為科學的主流做法包括統計分析、臨床咨詢和參考已有文獻,其中統計分析主要為開展單因素和多因素Cox分析,這與NICE文件[1]和Gregory等[14]的建議一致,少數研究(n=3)未使用上述方法而直接納入所有可匹配變量,可能會因納入過多的匹配變量而導致過矯。個體權重計算等步驟多通過R或SAS軟件實現(81.8%,n=9)。納入研究的匹配效度評估報告充分,所有研究均報告了ESS,但僅1項研究報告權重分布情況,71.43%的ESS/N值大于60%,整體匹配效度較為合理。納入研究的相對療效結局指標以時間事件類型的結局指標為主,通過Cox模型計算獲得HR,針對二分類指標的計算方法包括廣義線性模型、Logistic模型等,實際做法存在一定差異;非錨定研究的HR計算方法和思路大致相同,但有錨定研究提出兩種不同的相對療效計算思路;計算HR的研究僅少數(33.3%,n=3)考慮了PH假設,且做法尚不統一。多數(81.8%,n=9)研究開展了敏感性分析以分析不確定性,設置方面包括不同數據來源、患者亞組、匹配變量組合等。根據NICE文件建議,納入研究報告規范性總體良好但各條目間差距較大,對協變量分布的評估和不確定性測量報告較多(81.8%,n=9),45.5%的研究報告了協變量狀態評估,但僅1項研究報告權重分布。
在MAIC與藥物經濟學研究的銜接方面,在說明擬合外推方法的文獻中多數(85.7%,n=6)研究選擇目標藥品作為生存數據擬合外推的參照組,但一項NICE審查報告[35]指出這與MAIC方法原理相矛盾,由于調整后的HR反映對照組人群中兩種措施的相對療效,因此建議將對照藥品作為外推參照組。藥物經濟學研究對PH假設的考慮同樣較少,僅44.4%(n=4)的研究說明,且3項研究放寬或假定滿足PH。
綜上,對后續MAIC研究提出以下建議:① 非錨定MAIC研究使用廣泛,需注意其強假設,即兩種干預措施的療效差異完全來源于預后變量和效應修飾因子的不平衡,因此研究時需更加謹慎;② 通過文獻綜述系統篩選數據來源,并依據對照組納入與排除標準對IPD重新進行納排,若可獲得多個合適對照組的數據來源,可考慮進行敏感性分析;③ 通過統計分析、臨床咨詢和參考已有文獻等科學方法對匹配變量進行系統篩選,在錨定MAIC中納入預后變量,在非錨定MAIC中納入預后變量和效應修飾因子,針對存疑的變量可通過設置不同匹配變量情境研究不確定性;④ 通過報告ESS和權重分布以體現匹配效度,同時報告權重為0的樣本數量[1],并盡可能確保較高的ESS/N值以減少樣本流失;⑤ 通過加權Cox模型計算HR后需考慮PH假設,若無法統一標準做法檢驗PH假設時,需將其作為研究局限性進行報告;⑥ 對NICE建議的協變量分布評估、協變量狀態評估、權重分布、不確定性測量4項內容進行報告,提升報告規范性;⑦ 在使用MAIC獲得的HR進行生存數據擬合外推時,更加謹慎地選擇外推參照組,同時也需對是否滿足PH假設進行相應報告。
同時,本研究也存在一定的局限性,主要體現在系統評價僅納入了非小細胞肺癌領域的研究,研究結論可能存在偏倚,在進行其他領域的MAIC研究時需注意外推合理性。